Digest of Agile Software Development: Principles, Patterns, and Practices
目录
- Part 1. 敏捷开发
- Part 2. 敏捷设计
- Part 3. 薪水支付案例研究
- Part 4. 打包薪水支付系统
- Part 5. 气象站案例研究
- Part 6. ETS 案例研究
- chapter 28. Visitor 模式 / Decorator 模式
- chapter 29. State 模式
- chapter 30. ETS 框架,一个庞大的例子,还是 c++ 的,建议先看附录的状态机表示法
- 附录
chapter 1. 敏捷实践
论文档
- 编制文档是很花时间的,what’s more,保持文档和代码的同步更花时间
- Therefore,对团队而言,维护一份系统原理和结构的文档足矣 (自注:提供给外部的接口也要写一份)。这份文档应该是短小 (一二十页足矣) 且主题突出的 (包括系统的高层结构和概括的设计原理即可)
- 对团队新成员而言,最好的文档是代码和团队本身
- Martin 文档第一定律:不到迫不得已,可以不写文档
论计划
较好的做计划的策略:
- 为 next 2 weeks 做详细计划
- 为 next 3 months 做粗略计划
- 为 further in future 做极为粗糙的计划
论交付
- You’d better 尽早地、经常地交付
- 交付物是可工作的软件 (working software)。我们不赞成交付文档或者计划,我们也不认为那是真正的交付
论进度
只有 30% 的功能可用时,才能说进度完成了 30%
chapter 2. 极限编程概述
客户作为团队成员
- 谁是客户:XP 团队中的客户指定义产品特性并排列特性优先级的人
- 最好的情况是客户与开发人员在同一房间中工作 (自注:i.e. 及时沟通)
论需求
- 关注需求的最好时刻:第一个原型的问世
- 过早地捕获需求的特定细节,很可能导致做无用功或者产生不成熟的需求关注点
重构
- 代码的腐化:随着我们添加一个个新的 feature,添加越来越多的规则、保证措施,消除一个个 bug,代码的结构会逐渐退化 (自注:尤其是紧急的、临时救急的代码,真的很难有自制力再去整理它),最终成为难以维护的混乱代码
- 重构需要单元测试做底层保证
隐喻
- 隐喻是将整个系统的全局视图,它使得所有单独模块的位置和外观 (原文为 “shape”) 变得直观
- 隐喻简单来说就是用自己的语言来描述系统,用自己的方式来理解系统
- 隐喻可以很幼稚,比如说一个产生字符输出到屏幕的程序,可以把缓冲区当做卡车,屏幕是垃圾场,程序是垃圾制造者。这就是隐喻
- 当模块的外观与隐喻不符时,你就可以确定模块是错误的
chapter 4. 测试
- 编写单元测试是一种验证行为,也是一种设计行为,what’s more,它更是一种编写文档的行为
- 为了使程序是易于调用和可测试机的,它必要需要和它的周边环境解耦,这也是 TDD 的一个好处
- 单元测试编写初步:
- 按照 “便于我们自己阅读的方式” 来编写测试,简单说来类似隐喻,直接用自己的语言写出小白代码,比如:
LPaperCenter lpc = new LPaperCenter(); LPaper lp = lpc.receiveUserInput(params); lpc.saveToDB(lp); assertEquals(lpc.getTotal(), N); - 这种方法称为有意图的编程 (intentional programming),在测试中陈述你的意图
- 按照 “便于我们自己阅读的方式” 来编写测试,简单说来类似隐喻,直接用自己的语言写出小白代码,比如:
- 验收测试:单元测试是用来验证系统中单个机制的白盒测试,它无法验证系统作为一个整体工作时的正确性。此时需要验收测试,它是验证系统满足客户需求的黑盒测试,可以看做是一份关于特性 (feature) 的最终文档
chapter 5. 重构
- 重构,揭示 “使事物能够工作 (make things working)” 和 “使事物正确 (make things right)” 的区别
- 软件模块三职责:
- 完成功能
- 应对变化
- 和阅读代码的人进行沟通
- 其余部分 just read the book
chapter 6. 一次编程实践
- Never forget,过程是混乱的——过程中只要有人参与就都是这样
- “画” 出我们可能会遇到的输入,不管用什么形式。把这个输入作为第一组完整的测试数据
- UML 出可能的类,但不一定要完全按照 UML 来 code。UML 只是提供一种可能的思路,不要一上来就定义很多的类,多定义类的行为
- 从完整输入的合法子集入手,构造 Test Unit
- 完整输入的合法子集,指不一定要覆盖到所有可能的输入项,选一个简单的有实际意义的子集即可
- 比如完整输入是
(String, String, Object),那么(String, String, null)是一种可能的情况,那么它就是一个合法子集 - 逐步复杂这个合法子集到完整输入,一路复杂 Test Case 和实现
- 最初设计的类之间不要有双向依赖
- 所谓依赖不一定是组合关系,可以宽泛地理解成 “信息的依赖”
- 参数检查和异常:看涉及的接口被谁使用,如果是供外部调用,需要加防护;如果是内部调用,可以等到出现问题再加防护。但就目前的进度而言 (初步设计),可以不考虑,等到加了异常 Test Case 时你自然会加
- 不要过早考虑 SRP 之类的原则,让原型跑起来再说
- 对于特殊的业务规则,用一个 method 封装业务规则相关操作,名字当然要 semantic,必要时加注释
- 对于复杂、繁复的业务规则,自顶向下是好办法。这样的代码能一眼看到业务规则的全貌:
switch (processNum) { case 1: doProcess1(); break; case 2: doSubProcess2_1(); doSubProcess2_2(); break; } - 对于很长很长的
if条件,用一个 boolean method 代替吧 - 如果
methodB的结果会传递给methodA,但是还要经过调整,说明methodB设计有问题,比如int i = methodA(methodB() - 1);,明显methodB的设计有问题,或者有什么业务上的规则没有制定好 (比如 cursor 是指向第一个空 slot 还是最后一个非空 slot) - once it worked,考虑 SRP 这些事情,找可能的 refactor 点
chapter 7. 什么是敏捷设计
- Jack Reeves 认为系统的源码即是设计,represent 源码的图示是设计的附属物而不是设计本身
- 不要为过多的可能性做准备,大多数情况下不会带来回报,反而会使程序包含永远不会用到的结构而带来混乱
- 其余部分 just read the book
chapter 8. SRP:单一职责原则
SRP: Single Responsibility Principle
简单说,就是当有新需求来的时候,如果非要修改某个类的实现,不能因为不同的理由而修改同一个类。
比方说,一个类同时负责 “建立连接” 和 “读写数据” 两个功能。这次改需求要改连接方式,你修改的是这个类;下次改需求要修改读写格式,你修改的还是这个类,这就违反了 SRP。
chapter 9. OCP:开闭原则
OCP: Open-Closed Principle.
- Open for extension
- Closed for modification
SRP 说的是修改实现的原则;OCP 则是说:有新需求来的时候,应该只是添加子类或是接口实现 (Open),不应该去修改原有类的实现 (Closed)。
但是,不可能完全做到 Closed,不然的话就没必要提 SRP 了。
这里需要程序员判断哪些部分有潜在的新需求,对这些部分的设计要遵循 OCP。
判断潜在新需求的一个方法是:程序员自己诱发变化。TDD、原型、短迭代和持续交付都是良好的诱发变化的手段。
chapter 10. LSP:Liskov 替换原则
SRP 说的是修改实现的原则;OCP 说:有新需求来的时候,应该只是添加子类或是接口实现 (Open),不应该去修改原有类的实现 (Closed);LSP 则告诉你:怎样的子类和接口实现才是合格的子类和接口实现。
简单说来:Liskov 就是说子类应该可以无痛替换父类。看上去理所应当,但从另外一个角度来说,如果引入了一个子类,针对父类编程 (即利用多态的实现) 的部分需要做修改或者是做额外的兼容处理的话,那么只可能是两种情况:
- 父类设计不合理,针对父类的编程 (即利用多态的实现) 没有考虑所有的情况
- 引入的子类不合理,即这个子类不应该继承父类
书中的例子举得很好:从常识上说,Square IS-A Rectangle,但是如果把 Square 设计成 Rectangle 的子类,那么如何在 Square 中处理从 Rectangle 继承的 setWidth(int) 和 setHeight(int)呢?做兼容处理会带来很大的麻烦,而且对 rectangle.setWidth(2); rectangle.setHeight(5); assertEquals(10, rectangle.area()); 的断言也会失败。所以 Square 不应该设计成 Rectangle 的子类。从另一个角度来说,常识中的 IS-A 关系也不一定是很靠谱的。
一个继承关系,如果孤立来看,并不能看出它是否有设计问题;只有通过客户程序才能看出它是否有问题。比如前面,如果我们没有计算面积的需求,我们可能觉得对 Square 的 setWidth(int) 和 setHeight(int) 做点兼容处理也是可行的。OO 中的 IS-A 关系,应该是指父类和子类的行为方式一致,这个行为方式是由客户程序决定的。
书中另外一个例子也很说明问题,父类可以接受任何类型,但是引入的子类只能接受某个特定类型,这个继承关系就违反了 LSP。
检查是否违反了 LSP 有两个常见的方法:
- 子类中有退化方法,即父类的方法在子类中没有用处。一般的做法是子类覆写了某个父类的方法,但是是个空实现或是抛出
NotImpelmentedException之类的。有退化方法不一定代表违反了 LSP,但应引起注意 - 子类的方法声明抛出了父类没有声明的异常,一定是违反了 LSP
按理来说,接口和接口实现的关系也是要满足 LSP 的,但是感觉接口实现受编译器的限制比子类要大,违反 LSP 难度略大。但是在开发中需要警惕因为接口实现而去修改接口的做法。
chapter 11. DIP:依赖转置原则
SRP 说的是修改实现的原则;OCP 说:有新需求来的时候,应该只是添加子类或是接口实现 (Open),不应该去修改原有类的实现 (Closed);LSP 则告诉你:怎样的子类和接口实现才是合格的子类和接口实现;这些父类与子类、接口与接口实现可以看做是平行的结构,它们构成系统的各个层次,那么从纵向上看,高层模块和底层模块的关系应该有怎样的约束呢?DIP 说:层次间的依赖关系,箭头应该指向 (终止于) 抽象类和接口,而不是具体的类 (箭头从具体的类发出是没有问题的)。
DIP, Dependency Inversion Principle
- 高层模块不应该依赖于具体的底层模块 (死依赖),应该依赖于底层模块的抽象 (活依赖)。若是死依赖,改动会牵涉太多
- 抽象不应该依赖于细节 (比如具体实现);细节应该依赖于抽象
DIP 是框架 (framework) 设计的核心原则。框架提供给开发者的都是抽象,而实现都是由抽象派生的。
其实说白了就是“面向接口编程”这么简单。我们实际也经常这么做。比如 ServiceImpl 依赖于 Dao,而不是依赖于 DaoImpl。
另一种理解方式是:程序中所有的依赖关系都应该终止于抽象类或是接口。从这个规则可以可以得到三个过于严格的规则:
- 类的 field 中不应该有指向具体类的引用。创建其他类的实例,持有实例的引用,即是依赖了这个类。但是,如果这个类比较稳定,那么依赖于它也不不太会造成什么损害,比如,依赖于
String;如果依赖的类不稳定,我们就依赖于它的抽象,抽象是相对稳定的 - 任何类都不应该从具体类派生
- 任何方法都不应该覆写它的任何基类中已经实现的方法
高层策略是应用级别的抽象,它是不随细节变化的真理。换言之,它是我们对应用的代码描绘,它就是隐喻 (metaphore)。
书中的 Button/Lamp 例子很典型,Lamp implements SwitchableDevice,Button 持有一个 SwitchableDevice 实例,实际类型是 Lamp。这里我们创造的 SwitchableDevice 就是一个隐喻,我可以理解为它来源与我们生活的常识。
20180827 补充:来自 Java 8 函数式编程:
抽象不应依赖细节,细节应该依赖抽象。
让程序变得死板、脆弱、难于改变的方法之一是将上层业务逻辑和底层粘合模块的代码混在一起,因为这两样东西都会随着时间发生变化。
依赖反转原则的目的是让程序员脱离底层粘合代码,编写上层业务逻辑代码。这就让上层代码依赖于底层细节的抽象,从而可以重用上层代码。这种模块化和重用方式是双向的:既可以替换不同的细节重用上层代码,也可以替换不同的业务逻辑重用细节的实现。
chapter 12. ISP:接口隔离原则
SRP 说的是修改实现的原则;OCP 说:有新需求来的时候,应该只是添加子类或是接口实现 (Open),不应该去修改原有类的实现 (Closed);LSP 则告诉你:怎样的子类和接口实现才是合格的子类和接口实现;DIP 说:依赖关系都应该终止于抽象类或是接口。ISP 则是说:依赖于抽象是没错,但是这个抽象不能太胖。
比如说,一个接口有 10 个方法,但是,当你因为新的需求想添加一个新的实现类的时候,发现只用实现 7 个方法就可以了,另外 3 个方法只能给出退化 (degenerated) 实现了 (退化实现还有可能违反 LSP),那么我们可以说这个接口被三个不需要的方法污染了,也就是太胖了。
一个接口并不是生而就胖的,反而可以认为是客户端太刁钻了。试想,上面那个 10 个方法的接口,在新客户端出现之前,不是也工作得很好么?是因为新的客户端出现了,才显得胖。新客户端的引入,迫使我们对客户端进行整理,对客户端分类的过程也就是分离接口的过程。
ISP, Interface Segregation Principle
不应该强迫客户端依赖于 (i.e. 持有) 它们不用的方法,which 会导致所有客户端之间的耦合。
chapter 13. Command 模式 与 Active Object 模式
Command 模式
In object-oriented programming, the command pattern is a behavioral design pattern in which an object is used to represent and encapsulate all the information needed to call a method at a later time. This information includes the method name, the object that owns the method and values for the method parameters.
Four terms always associated with the command pattern are command, receiver, invoker and client.
- A command object has a receiver object and invokes a method of the receiver in a way that is specific to that receiver’s class.
- The receiver then does the work.
- A command object is separately passed to an invoker object, which invokes the command, and optionally does bookkeeping about the command execution. Any command object can be passed to the same invoker object.
- Both an invoker object and several command objects are held by a client object. The client contains the decision making about which commands to execute at which points. To execute a command, it passes the command object to the invoker object.
Using command objects makes it easier to construct general components that need to delegate, sequence or execute method calls at a time of their choosing without the need to know the class of the method or the method parameters. Using an invoker object allows bookkeeping about command executions to be conveniently performed, as well as implementing different modes for commands, which are managed by the invoker object, without the need for the client to be aware of the existence of bookkeeping or modes.

最基本的 Command 接口,没有任何变量,只封装了一个 void do()。有人认为它不符合面向对象的思想,因为它具有功能分解的味道:它只是把函数提升到了类的层面,它关注的仍然是函数而不是类。但是,我们使用起来可以不管这些。
文中提到了三种使用方式:
- Sensor(event)-Command Wiring
- Data-Command binding
- Command Stack (Redo/Undo)
Sensor-Command Wiring 中,因为多态,sensor 绑定一个 command 但无需知道这是具体是一个什么类型的 command,sensor 只需在检测到 event 时执行 command.do() 就可以了。这里也可以看做是一种 Event-Command Wiring。同样因为多态,这种 wiring 是设备无关的。从 web 开发的角度来看,我们可以想象用 ibatis 的 api 来代替 sensor,有 N 种数据库产品就有 N 套 Command 实现,我们选择数据库方言实际就是做了 Api-Command wiring。
Data-Command binding 给的例子是 Transaction 操作。Transaction 是包含了boolean validate() 和 void execute() 两个方法的 Command ,具体的 Transaction 实现要有与 pojo 一致的 field (否则没有 field 你咋验证?对非法的输入你也不好 new 一个 pojo 来验证),比如 AddEmployeeTransaction 需要有 String name 和 String address 这两个字段,与 Employee 类保持一致。
这样做有两个好处:
- 实体上的解耦:获取数据的代码、后台验证 (如果你在 js 中用这种模式,倒是也可以做到前台验证,而且可以和 dom 显示逻辑分离。我们一般也就是写个函数应付了,validate-ajax 或者 validate-commit,其实与这里的场景是一致的,只是没有做 command 封装而已) 和操作数据的代码、以及 pojo 本身这三者得到了分离
- 时间上解耦:对于某些不能立刻处理的数据,可以维持一个 Command 集合到特定时间再统一处理
当执行完一个 command.do(),可以把 command 压到 Command Stack 中,然后要 Undo 时,把这个 command 出栈,执行 command.undo() 即可。
文中的 Active Object 模式是结合了 Command 模式的一个例子,并没有单独说明什么是 Active Object。这里我们另开一节来说明。
文中的 ActiveObjectEngine,本质是一个 LinkedList<Command>,执行时就是 for (Command c : commandList) { c.do() }。
注意文中的 SleepCommand 并不是阻塞的,它在执行时,commandList 中的其他 command 是可以执行的。SleepCommand 这个名字实在是太容易引起误解了,它并不是 Thread.sleep() 的逻辑,更准确的名字应该是 DoItLaterCommand(long millseconds, ActiveObjectEngine e, Command todo),它保证 todo 在 millseconds 之后才执行。这里又要注意,这里的延迟执行,并不能保证一定是精确的在 millseconds 之后才执行,而是 至少 在 millseconds 时间后才会执行,至于中途到底会等多久,要看其后的任务会执行多久。
它的逻辑是:
- 第一次执行,初始化
startTime = now(); engine.addCommand(this) - 轮到第二次执行,检测是否有
now() - startTime > millseconds,若有,engine.addCommand(todo)(我觉得这里应该是直接todo.do());若无,继续engine.addCommand(this)(这是一种循环!)
这种技术常用来构建多线程系统。
Active Object 模式
Active Object 的组成:Proxy 实现外部的访问接口,在客户线程中被调用执行,而且用户只能看到 Proxy,Active Object 模式的其他组件对用户是透明的;Servant 在另外的线程完成操作。运行时,Proxy 把客户的调用信息封装到 “调用请求” (Method Request) (i.e. where Command Pattern works),通过调度者 (Scheduler) 把这个请求放到一个活动队列 (Activation Queue)。Scheduler 和 Servant 运行在另外的线程中,这个线程启动后,不断地从活动队列中得到 “调用请求” 对象,派发给 Servant 完成客户请求的操作。客户调用 Proxy 后马上得到一个预约容器 (Future),今后可以通过这个预约容器得到返回的结果。
下面的图说明了一个调用过程中的三个阶段:
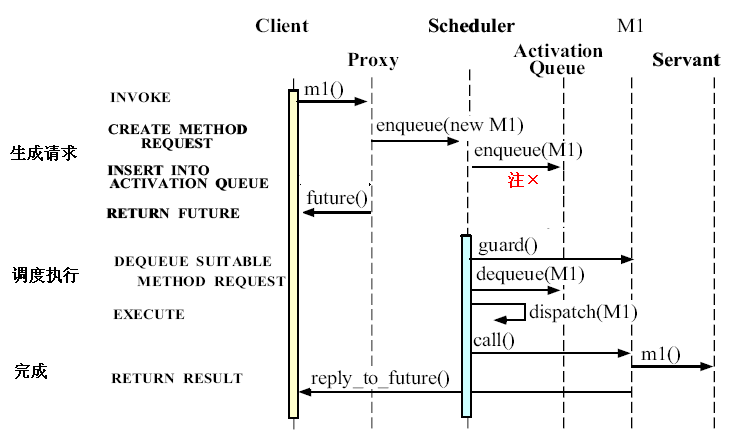
注×:原作 pdf 的图中,enqueue(M1) 的位置有误,入队操作应该在返回 Future 之前。崔超的翻译 中已经更正。黄色表现客户线程空间,绿色表示调度者线程空间。
- 构造 “调用请求”:在这个阶段,客户调用代理者的一个方法
m1()。“调用请求” 对象被创建,这个对象中包含了所有的参数。代理者把这个 “调用请求” 对象传递给调度者,调度者把它入队到活动队列。如果方法m1()有返回值,就返回一个预约容器 (Future),否则不返回。 - 调度执行:调度者的执行线程中,监控活动队列,当队列中的一个请求满足执行条件时,调度者把它出队,把一个执行者绑定到这个请求上。然后通过 “调用请求” 的
call()方法,call()再调用执行者的m1(),完成客户请求的操作。 - 完成:在这个阶段,如果有返回值,就把返回值存储到对应的预约容器中。然后调度者线程继续在活动队列中查找下一个要执行的 “调用请求”。客户就可以在预约容器中找到返回值。当 “调用请求” 和 “预约容器” 不再使用的时候,注意销毁,防止内存漏洞。
chapter 14. Template Method 模式 / Strategy 模式
这俩模式都是用来将通用的算法与具体的上下文分离,两者基本可以互换,只是 Template Method 是使用继承,Strategy 是使用组合。
Template Method 模式
其实用到抽象类的基本都是 template 模式了。
定义是:
In software engineering, the template method pattern is a behavioral design pattern that defines the program skeleton of an algorithm in a method, called template method, which defers some steps to subclasses. It lets one redefine certain steps of an algorithm without changing the algorithm’s structure.
一个直观的类比是 JUnit,Template 是 setup() / testXXX() / teardown(),具体怎么实现,你子类自己去填好了,我反正是把执行顺序先定好了。
Strategy 模式
strategy 与 template 最大的不同就是:template 是继承抽象类,strategy 是实现接口。比如每个人都要 “交个人所得税” (这是接口),但是 “在美国交个人所得税” (实现算法 1) 和 “在中国交个人所得税” (实现算法 2) 就有不同的算税方法。
定义是:
In computer programming, the strategy pattern (also known as the policy pattern) is a software design pattern that enables an algorithm’s behavior to be selected at runtime.
For instance, a class that performs validation on incoming data may use a strategy pattern to select a validation algorithm based on the type of data, the source of the data, user choice, or other discriminating factors. These factors are not known for each case until run-time, and may require radically different validation to be performed. The validation strategies, encapsulated separately from the validating object, may be used by other validating objects in different areas of the system (or even different systems) without code duplication.
更多内容见 Effective Java: item 21. 使用函数对象表示策略
chapter 15. Facade 模式 / Mediator 模式
Facade 模式
facade [fəˈsɑ:d] 的意思是 the face of a building, especially the front。
不像其他的模式有特殊的继承或者组合,facade 没有固定的结构,它的宗旨就是隐藏底层过于细节的实现或者设计得很烂的实现,提供一个统一的接口给上层。其实按这么说来,我们的 service 基本就是个 facade 了,因为 service 包装了过于细节的 dao 操作,然后提供统一的接口给了 controller。

是不是感觉这模式没啥了不起的?一般人都想得到好伐,就是一种思想而已。
Mediator 模式
facade 设计出来后,client 只用访问 facade 就好了,client 不知道也不关心底层的实现。
mediator 与 facade 不同,不管有没有 mediator,client 的访问方式不变 (就是说原来调哪些类哪些接口,现在还是调哪些类哪些接口)。所以 mediator 是与 client 无关的,它的作用是简化底层类之间的互相访问。
考虑 lp 项目的 js 代码,有 button 有 menu 有 dialog,点击一下各种 show、hide 写得神烦,比如 button_1.onclick() 要写 dialog_1.xxx(); dialog_2.zzz();,button_2.onclick() 要写 dialog_3.foo(); dialog_4.bar();,这时我们就可以定义一个 mediator 把 dialog_1.xxx(); dialog_2.zzz() 和 dialog_3.foo(); dialog_4.bar() 集中起来 (抽成两个方法即可),这样 button_1 和 button_2 就只和 mediator 交互,不用再调用具体的 dialog_n 了。
如果是这个结构的话,那 mediator 应该要包含 dialog_1、dialog_2、dialog_3、dialog_4 这 4 个成员,同时 button_1 和 button_2 各自要包含一个 mediator 成员。而且这个 mediator 并不会影响 client 调用 button_1.onclick() 和 button_2.onclick(),client 根本就不知道有 mediator 这回事。

这个图和我们的例子稍有点不符,想象成 “Colleague 是 Dialog 超类,ConcreteColleague 是 Dialog_N,单个 Dialog_X 都需要和其余所有的 Dialog_Y 交互” 就可以了。
这篇 Mediator Pattern 写得不错,还提了一个 chatroom 的例子:
The chat application is another example of the mediator pattern. In a chat application we can have several participants. It’s not a good idea to connect each participant to all the others because the number of connections would be really high, there would be technical problems due to proxies and firewalls, etc… . The most appropriate solution is to have a hub where all participants will connect; this hub is just the mediator class.
Participants:
- Chatroom (Mediator) - Defines the interface for interacting with participants
- ChatroomImpl (ConcreteMediator) - implements the operations defined by the Chatroom interface. The operations are managing the interactions between the objects: when one participant sends a message, the message is sent to the other participants.
- Participant (Colleague) - defines an interface for the participants.
- HumanParticipant, Bot (ConcreteColleague) - implements participants; the participant can be a human or a bot, each one having a distinct implementation but implementing the same interface. Each participant will keep only a reference to the mediator.
还有一个类比就是塔台,“飞机甲” 不需要向其余的 “飞机乙丙丁” 通告飞行高度,它只需要向塔台 (mediator) 通报就可以了。
chapter 16. Singleton 模式 / Monostate 模式
Singleton 模式略过
Monostate 模式
monostate 的思想很简单,它就是把对象的状态,i.e. 所有的 field 都用 static,这样不管你有多少个 instance,状态都是一样的。我觉得 monostate 不能脱离 singleton 来看,不然有点难想象它的应用场景。
Singleton vs. Monostate (pdf) 有说:
Singleton is best used when you have an existing class that you want to constrain through derivation, and you don’t mind that everyone will have to call the instance() method to gain access.
Monostate is best used when you want the singular nature of the class to be transparent to the users, or when you want to employ polymorphic derivatives of the single object.
monostate 比 singleton 好的一个地方就是继承,因为 monostate 的子类自然也是 monostate (如果子类不加新 field 的情况下),而 singleton 的子类……首先你一般不会想到要继承 singleton,singleton 也不是为继承而设计的,其次父类的 private constructor 你不能用,子类的构造会有点难处理。
此外,monostate 对客户端程序来说是透明的。客户端程序可以随意创建对象,但是对象的状态是唯一的,这一点客户端不用知道。
chapter 17. Null Object 模式
和 Effective Java: item 43. 返回零长度的数组或者集合 instead of null 是同一个思想。考虑一个 query 但是没有找到任何记录,你返回 null 或是抛一个异常对上层调用代码都很不好处理,这时我们可以 return 一个 null object。
null object 在实现上比空列表要复杂一点,它是正常业务类的 sibling,这要求正常的业务类有一个父类或是接口,比如 LP,正常的业务类是 CustomLP,那么对应的 null object 类就是 NullCustomLP。
此时,可以给 LP 定一个方法,比如 isNull() 或是 isUsable() 之类的,给上层调用代码判断一下这个 LP 到底是 CustomLP 还是 NullCustomLP。
然后 NullCustomLP 可以设计成单例,或是设计成 LP 的内部类 (接口也可以有内部类,所以 LP 是接口也无所谓) 然后通过 LP 的一个 public static field 暴露出来,比如 LP.NULL。
chapter 18. 薪水支付案例研究:第一次迭代开始
数据库是实现细节!应该尽可能地推迟考虑数据库。
对于数据库的倾向 (predisposition) 会再次引诱我们去考虑关系数据库表中的记录规划或者字段结构。
应用设计不应该依赖于任何特定类型的数据库 (19章第7节)
这一段要与 设计 PO 的一些经验 连起来看。其实我们考虑从 DB 入手很多情况下是出于:
- 对一表多对象、Transaction 管理等知识的不足
- 总有表字段会遗漏或者后期需求要加 field 会干扰你的设计
- 对设计 PO 的思考不够,换言之就是懒,因为 PO 设计成表结构一样是最方便的,而且这样反过来会影响表结构的设计质量
解决了这些问题,应该可以做到后处理数据库细节。可能会遇到:
- 业务类和 DAO 操作的对象类有区分,因为表结构可能与业务类差别很大
- 或者直接在 DAO 中对业务类做转置,不单独设计 DAO 操作的对象类,这可能需要对 ORM 框架的精通
总之,要做到熟悉 ORM 框架,并且不要偷懒。
从 图18.2 到 图18.6 再到 图18.12,我们应该养成一个习惯是:对于这些业务类,多问自己 What do they have in common? 而不是简单的 What fields do they have in commom?
chapter 20. 包的设计原则
- 前 4 个原则的原文描述见这篇 pdf:Granularity
- 后 2 个原则的原文描述见这篇 pdf:Stability
- 2020 年补充说明:这两篇文章仍然可以通过 Wayback Machine 搜索到 (直接搜索 link address)
粒度:包的内聚性原则
REP: 重用发布等价原则
REP: Reuse-Release Equivalence Principle
其实这个原则的目的是要说:你 reuse 代码的时候不要去 copy 代码,应该使用 libraray。然后引出:
Thus, I can reuse nothing that is not also released
- copy 的代码不是 released 的代码
然后顺理成章,package 是 release 的单位,进而也是 reuse 的单位:
And so, the REP states that the granule of reuse can be no smaller than the granule of release. Anything that we reuse must also be released. Clearly, packages are a candidate for a releasable entity. It might be possible to release and track classes, but there are so many classes in a typical application that this would almost certainly overwhelm the release tracking system. We need some larger scale entity to act as the granule of release; and the package seems to fit this need rather well
- 这里 tracking system 感觉就是 svn 之类的
再然后书中和 wiki 都提到了:
Either all of the classes inside the package are reusable, or none of them are.
这一句才是最好用的
CRP:共同重用原则
CRP: Common Reuse Principle
The classes in a package are reused together. If you reuse one of the classes in a package, you reuse them all.
换句话说:
The CRP states that classes that tend to be reused together belong in the same package together. It is a way of helping us decide which classes belong in which package.
- 一个很好的例子是:容器类和迭代器类应该放到同一个 package
然后作者有补充说:
Thus, I want to make sure that when I depend upon a package, I depend upon every class in that package.
CCP:共同封闭原则
CCP: Common Closure Principle
The classes in a package should be closed together against the same kinds of changes. A change that affects a package affects all theclasses in that package and no other packages.
“and no other packages” 从 SRP 的角度来理解的话也就是:Package A 只为 Reason A 修改,Package B 只为 Reason B 修改,不能有交叠。
CCP states that the package should not have more than one reason to change. If change were to happen in an application dependent on a number of packages, ideally we only want changes to occur in one package, rather than in a number of them.
This helps us determine classes that are likely to change and package them together for the same reasons. If the classes are tightly coupled, put them in the same package.
稳定性:包的耦合性原则
ADP:无环依赖原则
ADP:Acyclic Dependencies Principle
The dependency structure between packages must be a Directed Acyclic Graph (DAG). That is, there must be no cycles in the dependency structure.
出现依赖环的后果:
- 包之间的依赖加重
- 修改一个包对其他包的影响变大
消除依赖环的方法:
- 能 DI 的就 DI
- 提取公共依赖
SDP:稳定依赖原则 / SAP:稳定抽象原则
SDP: Stable Dependencies Principle
The dependencies between packages in a design should be in the direction of the stability of the packages. A package should only depend upon packages that are more stable that it is.
SAP: Stable Abstractions Principle
Packages that are maximally stable should be maximally abstract. Instable packages should be concrete. The abstraction of a package should be in proportion to its stability.
以上两个原则要连起来看,而且书上还提出了量化分析方法,非常具有 paper 的意味,值得一读。
chapter 21. Factory 模式
简单说一下。factory 模式的目的就是减少对具体类的依赖,比如你 new Circle() 又 new Square(),你就依赖了两个类,你改成 shapeFactory.newCircle() 和 shapeFactory.newSquare(),你就只依赖 ShapeFactory 这一个类。调用类减少对其他类的依赖,自然也减少了因为其他类变动而修改调用类的可能性。
chapter 22. 薪水支付案例研究 (第2部分)
对比 图22.1 和 图22.2,抛去 Transaction 不谈,最大的区别是:Method、Schedule、Classification、Affiliation 这四大 PO 的抽象类,原来是分布在 4 个包中的,现在集中到 Payroll Domain 包,这个好处是显而易见的。我们自己在定 PO 的时候基本都没有抽象类,所以根本就不会考虑这个问题。
后面拿 chapter 20 的计量方法计算了一下,顺带介绍了几个依赖计算工具,然后引入 factory 模式又计算了一遍,不得不说这 paper 的感觉真是好~
题外话一下,这章给人一个新的思路就是:咦,包图原来可以这么用~ 我们自己分包是不会考虑这么多的,包图在学习的时候也不知道有啥用 (不是我没认真学),现在多了一种选择,就是初步实现之后,导出包图,按照这几个原则考虑一下,有必要的话就重新划分。这是一个切实可行的步骤,毕竟从一开始就考虑那么多原则太强求。
chapter 23. Composite 模式
与 “组合优于继承” 的组合不是同一概念。简单说,composite 模式就是用一个 composite 类来代替接口集合。
还是用 Shape、Circle、Square 的例子。调用类可能要多个 Circle 或 Square,这是我们常见的做法是定一个 List<Shape> list = new ArrayList<Shanpe>();。如果用 composite 模式的话就是:
public class CompositeShape implements Shape {
private List<Shape> list = new ArrayList<Shanpe>();
public void add(Shape s) { ... }
public void remove(Shape s) { ... }
...
}
然后调用类就可以只持有一个 Composite 对象就可以了。同时 CompositeShape 还可以 add(CompositeShape) 自行嵌套,可以亦链亦树。
wiki 也说:
In software engineering, the composite pattern is a partitioning design pattern. The composite pattern describes that a group of objects are to be treated in the same way as a single instance of an object. The intent of a composite is to “compose” objects into tree structures to represent part-whole hierarchies. Implementing the composite pattern lets clients treat individual objects and compositions uniformly.
When dealing with Tree-structured data, programmers often have to discriminate between a leaf-node and a branch. This makes code more complex, and therefore, error prone…
chapter 24. Observer 模式
书上包括一个如何渐进到模式的例子。但这个例子我看得头晕,不如直接看 Observer 模式是咋回事)
chapter 25. Adapter 模式 / Bridge 模式
书上起始是 Abstract Server 模式,作用其实是为了引出后面两个模式,这里略过
Adapter 模式
Adapter 模式可以直接 看这个
Bridge 模式
wiki 有说:
The bridge pattern is a design pattern used in software engineering which is meant to “decouple an abstraction from its implementation so that the two can vary independently”……
……The bridge pattern is useful when both the class as well as what it does vary often. The class itself can be thought of as the implementation and what the class can do as the abstraction. The bridge pattern can also be thought of as two layers of abstraction.

Stack Overflow 有说:
The Bridge pattern is a composite of the Template and Strategy patterns.
因为有 Abstract,所以明显是 Template。然后 Implementor 又可以看成是 Strategy。
Stack Overflow 还举了个例子:
Say you must implement a hierarchy of colored shapes. You wouldn’t subclass Shape with Rectangle and Circle and then subclass Rectangle with RedRectangle, BlueRectangle and GreenRectangle and the same for Circle, would you? You would prefer to say that each Shape has a Color and to implement a hierarchy of colors, and that is the Bridge Pattern.

Bridge 模式和 Adapter 模式 是有一点像,不同之处在于:
| x | Bridge 模式 | Adapter 模式 |
|---|---|---|
| 暴露的接口 | client 调用的是 Abstraction (抽象类) | client 调用的是 Target (接口) |
| 具体实现的接入点 | Abstraction 直接包含 Implementor | Adapter (implements Target) 包含或继承 Adaptee |
| 类图形状 | 看做梯形的话,真的很像是一座钢结构的 bridge | Target-Adapter-Adaptee 构成一个倒三角 |
还是来自上面 Stack Overflow 的说明:
At first sight, the Bridge pattern looks a lot like the Adapter pattern in that a class is used to convert one kind of interface to another. However, the intent of the Adapter pattern is to make one or more classes’ interfaces look the same as that of a particular class. The Bridge pattern is designed to separate a class’s interface from its implementation so you can vary or replace the implementation without changing the client code.
chapter 26. Proxy 模式 / Stairway To Heaven 模式:管理第三方 API
Proxy 模式
26.1.3节 的内容最多,但是我不是很理解它这个例子,无法把它联系到我们的 Service / DAO 结构上。下面单独说一下 Proxy 模式。

其实本身是很简单的,而且尼玛巨像 Decorator 有没有?Stack Overflow 上提到了这两者的区别:
- Proxy may not instantiate wrapping object at all (e.g. ORMs prevent unnecessary access to DB if object fields/getters are not used) while Decorator always hold link to actual wrapped instance.
- Decorator usually used to add new behavior to old or legacy classes by developer itself. Proxy usually used by frameworks to add security or caching/lazing and constructed by framework (not by regular developer itself).
这篇 The Proxy Pattern 还提到了 Proxy Chain,有点意思,可以联想到 Struts2 的 interceptor stack。
wiki 还提了一句:
A well-known example of the proxy pattern is a reference counting (引用计数) pointer object.
注意 “a reference counting pointer object” 这个表述真的很啰嗦,还容易导致误解 (尼玛 “pointer object” 是啥),其实 “a reference-counted pointer” 就已经是 an object which tracks the number of reference-counted pointers referencing a given object, and destructs the tracked object when this number drops to zero。
Stairway To Heaven 模式
Stairway To Heaven 模式要求多重继承,给的例子是 c++,有兴趣自己看下
chapter 27. 案例研究:气象站
图27.6 中 Barometric Pressure Trend Observer 的提出值得学习,它把 “大气压趋势算法” 单独隔离出来了。这要是我们自己来设计,肯定是和 Barometric Pressure Observer 混到一起了。
比较 27.2.2 定期测量 的 Schedule 和 27.2.6 再次考虑 Schedule 的 AlarmClock,其实 Schedule 的问题是:
- 时间是
Schedule自己定的 - 看不出来
Schedule是怎样持有Sensor的 (但看作者的意思肯定是没有下面主动注册来得好)
换成 AlarmClock 之后变成了:
Sensor自己主动注册到AlarmClock- 注册的时候就顺带把时间参数带上了
程序27.2 的 factory 用得有点意思,它是直接把 factory 传给了 PO 的构造器,在构造器里用 factory 初始化 PO 的单例。
剩下的部分不说了。这一章是个很大的完整的例子,最好一口气弄懂,会有点启发。可以先从 27.4 节开始。
chapter 28. Visitor 模式 / Decorator 模式
Visitor 模式
我觉得书上的图比 wiki 来的好:

简化的代码是:
public class UnixModemConfigurator implements ModemVisitor {
@Override
public void visit(HayesModem hm) {
hm.setConfigString("Hayes");
}
@Override
public void visit(ZoomModem zm) {
zm.setConfigString("zoom");
}
}
public class HayesModem implements Modem {
private String configString;
@Override
public String getConfigString() {
return configString;
}
public void setConfigString(String configString) {
this.configString = configString;
}
@Override
public void accept(ModemVisitor v) {
v.visit(this);
}
}
public static void main(String[] args) {
Modem hayes = new HayesModem();
Modem zoom = new ZoomModem();
ModemVisitor umc = new UnixModemConfigurator();
hayes.accept(umc);
zoom.accept(umc);
System.out.println(hayes.getConfigString());
System.out.println(zoom.getConfigString());
}
wiki 的说法是:
The visitor design pattern is a way of separating an algorithm from an object structure on which it operates. A practical result of this separation is the ability to add new operations to existing object structures without modifying those structures. It is one way to follow the open/closed principle.
这也说明了应用场景和使用 visitor 的初衷:
- 我想给每个 Modem 子类都加个
setConfigString()的功能 (the ability to add new operations to existing object structures)。 - 但是我觉得把这个逻辑 (或者上面说的 “an algorithm”) 集中到一个类中比较好,不想分散到各个子类 (separating an algorithm from an object structure)。
- 或者我觉得这个逻辑和
Modem接口无关,我并不想在Modem子类中关注这个setConfigString()具体是怎么实现的。
Thinking in C++, Volume 2 的说法是:
The goal of Visitor is to separate the operations on a class hierarchy from the hierarchy itself.
If you need to add member functions to the base class, but for some reason you can’t touch the base class. How do you get around this? Visitor builds on the double-dispatching scheme which allows you to effectively extend the interface of the primary type by creating a separate class hierarchy of type Visitor to “virtualize” the operations performed on the primary type. The objects of the primary type simply “accept” the visitor and then call the visitor’s dynamically bound member function. Thus, you create a visitor, pass it into the primary hierarchy, and you get the effect of a virtual function.
注意我写的简化的代码和书上的有些区别:
- 书上
Modem接口并没有getConfigString()方法,这样一来在main里就不能用Modem的多态了,你要么定义具体的Modem子类实例,要么 cast 一下。 - 书上各个
Modem子类并不是统一的setConfigString()方法,而是直接把 field 暴露出来的了,而且 field 名字也不相同,有的是configurationString,有的是configurationValue等等。
另外注意几点:
UnixModemConfigurator里并没有用(并不是你想用就能用,因为 Java 的方法参数根本就不支持多态!否则就是 Double Dispatch 了),也没有 if-else 判断子类型,而是每个Modem的多态Modem子类单独写了一个visit方法,这样如果有 N 个Modem子类就要写 N 个visit重载方法。这必然是比 if-else 判断子类型来得要好。- 我自然是可以定义多个
ModemVisitor实现,都让Modem去accept。
Acyclic Visitor 模式
注意到上面的类图里是有依赖环的,而且还有这么一个问题:如果我有一个 Modem 子类不需要这个 setConfigString() 功能咋办?这时可以用 Acyclic Visitor 模式:

具体的变化是:
ModemVisitor变成了标记接口。- 单个
Modem子类要实现一个XxxModemVisitor接口,只实现一个public void visit(XxxModem xm)方法。 - 单个
Modem子类实现accept(ModemVisitor v)时需要把vcast 成具体的XxxModemVisitor。 UnixModemConfigurator多重implements XxxModemVisitor, ...。- 此时如果
ZoomModem不需要setConfigString()功能,你就不要定义ZoomModemVisitor,UnixModemConfigurator也不要去implements ZoomModemVisitor就好了。
书上举了个很好的比喻,这里是有 3 个 Modem 子类,假设我除了 UnixModemConfigurator 还有个 Win32ModemConfigurator,那么一般的 visitor 模式就构成了一个 $2 \times 3$ 矩阵,而 Acyclic Visitor 模式则构成一个 $2 \times 3$ 的稀疏矩阵 (因为可以有 Modem 子类不实现 ZzzModemConfigurator 的功能)。
Extension Object 模式
Extension Object 模式你可以看做是 Acyclic Visitor 模式的变体,而且 PO 是持有 <VisitorName, VisitorObj> 这样一个 Map,可以进一步细分 Visitor 逻辑
Visitor 模式使用场景
书上给了个 “生成报表” 的例子,报表 visitor 使数据类中不包含任何产生报表的逻辑 (想象我们的 PO 和 JSON 生成逻辑……),而且可以通过不同的 visitor 支持不同格式的报表输出。末了又提了一句:
一般来说,如果一个应用程序中存在需要以多种方式进行解释的数据结构,就可以使用 Visitor 模式。
Decorator 模式
还是老样子,Decorator 模式具体见这篇。
不过书上提了个很有意思的观点:
每当使用者提出一些其他的古怪要求时,就必须对它 (业务类) 进行修改吗?
这里其实是说我们要 SRP。不过也从侧面说明:Decorator 适合封装古怪的业务逻辑。这应该也算是开发人员对业务概念的一种捍卫。
然后书中还提了下 Decorator Hierarchy,多层 Decorator 封装不同层面的业务逻辑。
chapter 29. State 模式
传统的处理 FSM 的做法是:
- 大量的 if-else
- 自己写 Transition、Event 这些类并自己设计并解析状态迁移表
这两种方法都很繁,所以我们要有 State 模式。
书上的例子简单清晰,假设我们面对的是闸机 Turnstile 的状态:
| Current State | Event | Action | Next State |
|---|---|---|---|
| Locked | coin | unlock | Unlocked |
| Locked | pass | alarm | Locked |
| Unlocked | coin | thankyou | Unlocked |
| Unlocked | pass | lock | Locked |
类图如下:

实现要点:
State接口要实现event(StateOwner)方法StateOwner(i.e. Turnstile) 要实现event()和action()方法;action()方法可以委托给 util 类实现StateOwner包含一个State实例,在实现event()时实际调用state.event(this),然后state.event(this)里实际操作StateOwner
画个时序图看看:

代码如下:
public class LockTurnStileState implements TurnstileState {
@Override
public void coin(Turnstile t) {
t.unlock();
t.setUnlocked();
}
@Override
public void pass(Turnstile t) {
t.alarm();
}
}
public class UnlockedTurnstileState implements TurnstileState {
@Override
public void coin(Turnstile t) {
t.thankyou();
}
@Override
public void pass(Turnstile t) {
t.lock();
t.setLocked();
}
}
public class Turnstile {
private static TurnstileState LOCKED = new LockTurnStileState();
private static TurnstileState UNLOCKED = new UnlockedTurnstileState();
private TurnstileState currentState = LOCKED;
// changeState()
public void setLocked() {
currentState = LOCKED;
}
public void setUnlocked() {
currentState = UNLOCKED;
}
// event()
public void coin() {
currentState.coin(this);
}
public void pass() {
currentState.pass(this);
}
// action()
public void lock() {
TurnstileUtil.lock();
}
public void unlock() {
TurnstileUtil.unlock();
}
public void alarm() {
TurnstileUtil.alarm();
}
public void thankyou() {
TurnstileUtil.thankyou();
}
}
写到这里,我不禁觉得我的 LP 项目 create、edit 那一块的逻辑真的很适合用 State 模式:StateOwner 是 EditPage,State 是 UploadPic、UseSystemPic 之类的,action 是 createLP、saveLP、writeResponse 之类,event 就靠参数来判断好了……简直不能更适用!
enum 版本的 State
我突然觉得用 enum 来实现 State 应该是个不错的选择,所以自己研究了下,发现这是可行的,原因有:
- enum 实例可以带方法
- enum 可以实现接口
代码如下:
public enum EnumedTurnsitleState implements TurnstileState {
EnumedLockedTurnstileState {
@Override
public void coin(Turnstile t) {
t.unlock();
t.setUnlocked();
}
@Override
public void pass(Turnstile t) {
t.alarm();
}
},
EnumedUnlockedTurnstileState {
@Override
public void coin(Turnstile t) {
t.thankyou();
}
@Override
public void pass(Turnstile t) {
t.lock();
t.setLocked();
}
};
}
这样一来,Turnstile 里就可以不用 TurnstileState 的多态了,直接 EnumedTurnsitleState currentState = EnumedLockedTurnstileState; 好了。
SMC: State Machine Compiler
State 模式也是有缺点的:
- State 子类的实现工作繁杂
- 逻辑分散,无法在一个地方看到整个状态机逻辑
问了解决问题 1,Bob 大叔提供了工具 SMC (State Machine Compiler) 可以自动生成 State 模式代码框架,我隐约觉得有朝一日总会用到的……
应该在哪些地方适用 State 模式
- GUI 交互控制 (你看,我就说吧,LP)
- 比如连续三次输入密码错误的处理逻辑
- 比如拖拽画图的状态:
MouseDown、Dragging、MouseLeave
- 类似网络传输的场景 (三次握手什么的),类似于
EstablishConnection、SendPackage、CloseConnection这样的状态
附录 A. UML 表示法 I: CGI 示例
UML 没啥好讲的,记录下小知识点:
- UML 的 “unified” 表示的是 “统一了结构化分析与结构化设计”
- 用例的扩展点 (extension point) 其实是个标志,表示 “快来几个用例来扩展 (
<<extend>>)我”,比如:- 父用例 UC#2 是 “在线支付”
- extension point 是 “选择支付方式”
- 子用例 UC#2.1 是 “支付宝支付”,UC#2.2 是 “网银支付”
附录 B. UML 表示法 II: 统计多路复用器
状态图的示例讲得很好,特别记录一下。

[A]-Y->[S]: 会触发 [S] 内部初始节点到 [C] 的迁移,和直接[A]-V->[C]的过程是不同的[B]-Q: [S] 状态终止,激发 [S]->[A] 的未标注迁移,最后到达 [A] (这应该是默认行为,自动找未标注的迁移)[S]-Z->[D]: [S] 状态并没有终止 (我觉得可以叫状态退出),而且这是个简写,表示:无论是 [C] 还是 [B],只要激发迁移 Z (等同于发生事件 Z),都会到达 [D][D]-T->(H): (H) 是 history 标记,表示:如果 [S] 有历史状态记录,则 [S] 中最近的一个活动状态被重新激活:- 比如最近一次有
[C]-Z->[D],则 [S] 最近的一个活动状态是 [C],则这个 (H) 最终会到达 [C] [B]-Q会清空历史状态记录- 若 [S] 从来没有被进入过,则也没有历史状态记录
- 比如最近一次有
(H)->[B]: 表示若没有历史状态记录,这条未标注的迁移就会被激发,最终到达 [B]
Comments